
日本語の文字列が判定に失敗する
Power Automate の「条件」アクションで、分岐を判定する値として日本語の文字列(例:「承認済」「却下」)を設定すると、正しく判定されず、想定した結果にならないことがあります。これは、内部的に日本語の文字列が UTF-8 エンコードされているためです。
エンコードとは
エンコードとは、一般的にはデーターを別形式に変換することを指しますが、この場合、二バイト文字(日本語や中国など)を一バイト文字(英語など)に変換し、プログラム上で扱いやすくすることを指します。
Power Automate でのエンコードは「UTF-8」で行われており、例えば「あいうえお」をエンコードすると「44GC44GE44GG44GI44GKCg==」になります。そのため「条件」アクションで指定する値を、「あいうえお」ではなく「44GC44GE44GG44GI44GKCg==」として指定してやれば、意図した結果を得ることができます。
UTF-8 へのエンコードは、Web上で行えるサイトがいくつもありますので、それを利用すると良いと思います(例:https://www.benricho.org/moji_conv/16-URLencode_UTF-8.html)
あとで分かるよう設計を工夫する
UTF-8 でエンコードして指定すれば問題は解決…ではあるのですが、このままでは後から設計を見直した際、一体何を条件値としたのか一見してわからなくなります。都度、デコード(エンコードの逆処理)して「44GC44GE44GG44GI44GKCg==」を「あいうえお」に戻して確認する必要があります。それでは少々不便なので、設計を工夫してみます。
まず「変数を初期化する」アクションで、名前を元の文字列に、値をエンコード後の文字列にしていします。
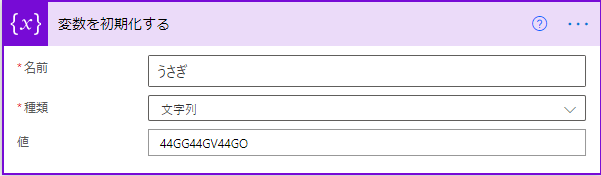
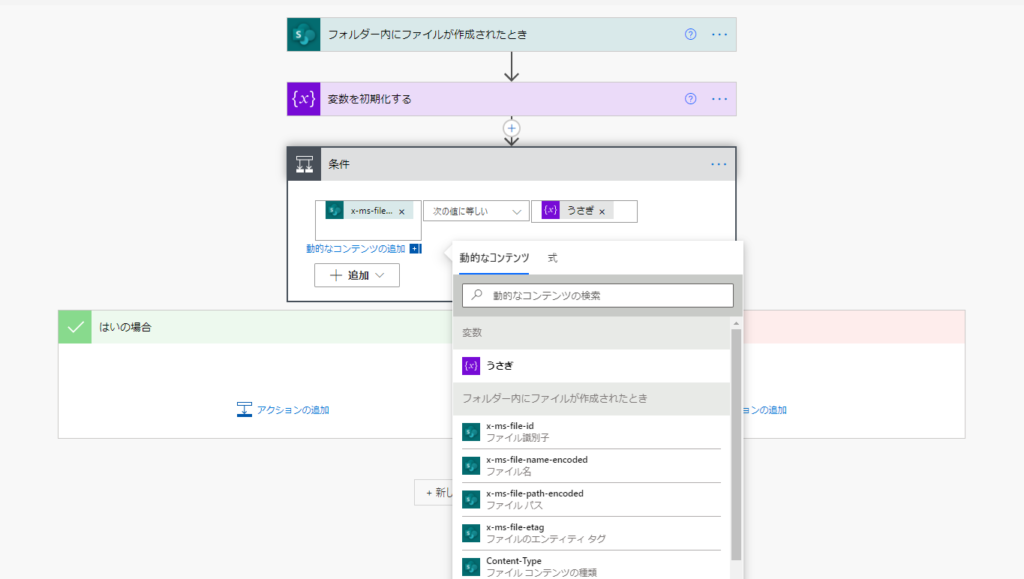
これで「うさぎ」を変数として指定できたので、「条件」アクションで値を日本語文字列のまま指定できます。
まとめ
ついつい忘れがちで焦るのですが「条件の値はできるだけ英数字にしておく」「日本語はUTF-8で要エンコード」と覚えておくと、設計時のトラブルを防ぐことができると思います。その上で、変数指定をつかって設計の可視性をあげておくと、あとから引き継ぐ方がちょっとだけハッピーかもしれません。


